Shihao Zhang, Weiyao Lin, Ping Lu, Weihua Li, Shuo Deng
Department of Electronic Engineering
Shanghai Jiao Tong University, China
wylin@sjtu.edu.cn
Object detection is an important yet challenging task in video understanding & analysis, where one major challenge lies in the proper balance between two contradictive factors: detection accuracy and detection speed. In this paper, we pro-pose a new adaptive patch-of-interest composition approach for boosting both the accuracy and speed for object detection. The proposed approach first extracts patches in a video frame which have the potential to include objects-of-interest. Then, an adap-tive composition process is introduced to compose the extracted patches into an optimal number of sub-frames for object detec-tion. With this process, we are able to maintain the resolution of the original frame during object detection (for guaranteeing the accuracy), while minimizing the number of inputs in detection (for boosting the speed). Experimental results on various datasets demonstrate the effectiveness of the proposed approach.
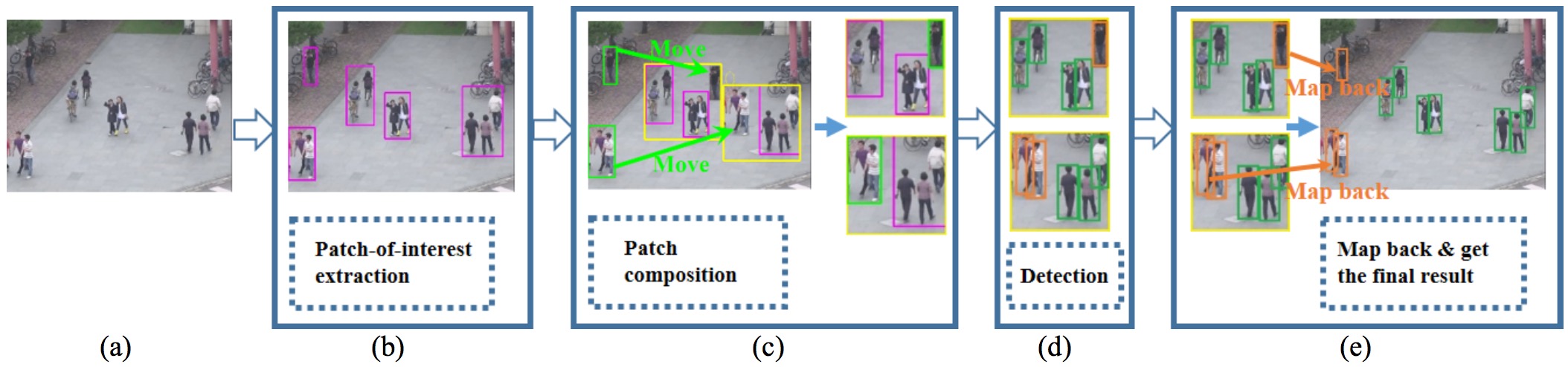
Fig. 1 Framework of the proposed approach. (a) The input image. (b) Detected patches. (c) The patch composition (left) and sub-frames (right). (d) Detection results on sub-frames. (e) Map back and get the final result on the original image.
This figure shows the framework of the proposed approach. We first extract patches-of-interest in an original frame, where each patch-of-interest correspond to a region including potential objects-of-interests (cf. Fig.1(b)). Then a patch composition process is performed, which automatically finds a set of optimal locations for sub-frames and moves the extracted patches into these sub-frames (cf. Fig.1(c)). Finally, the composited sub- frames are input the ConvNet-based detectors to obtain detection results (cf. Fig.1(d)), and the detection results in sub-frames are simply mapped back into the original frame to achieve the final result (cf. Fig.1(e)).

Fig. 2 Procedure of extracting patches: (a) The original image, (b) The foreground after morphological filtering, (c) The image including patches.
In this paper, since we mainly focus on surveillance scenarios whose backgrounds are normally static, we use foreground extraction followed by simple morphological filtering to detect potential regions, as shown in Fig.2(b). Then we simply derive a bounding box for each connected potential region as the extracted patch as shown in Fig.2(c).
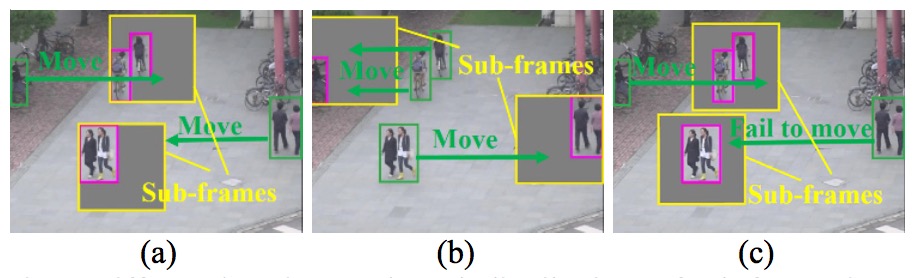
Fig. 3 Different locations and patch distributions of sub-frames in an image: (a) Detected patch locations with the sub-frame location term and the patch distribution term. (b) Detected patch locations with the patch distribution term, but without the sub-frame location term. (c) Detected patch locations with the sub-frame location term, but without the patch distribution term.
We apply an adaptive composition process to composite the extracted patches into an optimal number of sub-frames for object detection. The two key points are "Sub-frame location term" and "Patch distribution term". The former means that we view locations consisting of a large number of patches-of- interest with large sizes as the proper locations of sub-frames, since it can greatly reduce the number and total size of uncovered patches. While considering the latter, we notice that the subframes in Fig. 3(a) and Fig. 3(c) cover the same patches, however, the subframe in (a) is better than Fig.3 (c), since sub-frames in Fig. 3(a) have more blank regions where more uncovered patches can be moved in.




Fig. 4 Examples of composited sub-frames by our approach in different datasets.
This figure shows examples of composited sub-frames by our approach in different datasets. Their sizes vary from 300 * 300 to 500 * 500 with much detail information.
In order to evaluate the effectiveness of our approach, we compare the following four methods. (1) Directly down-sample the original frames into 300×300 and input into ConvNet-based detector (DS). (2) Divide each frame into 300×300 non-overlapping sub- frames and input them into ConvNet-based detector respectively (DIV). (3) Our approach which uses sub-frames with 300×300 sizes to cover patches-of-interest (Our-S). (4) Our approach which uses sub-frames with 500×500 sizes to cover patches-of-interest (Our-L) and then down- samples them to 300×300 for detection. This method can be viewed as a fast version of our approach, which utilizes larger sub-frame sizes to cover more patches, so as to reduce the number of sub-frames in later detection steps.
Table 1

Table 2
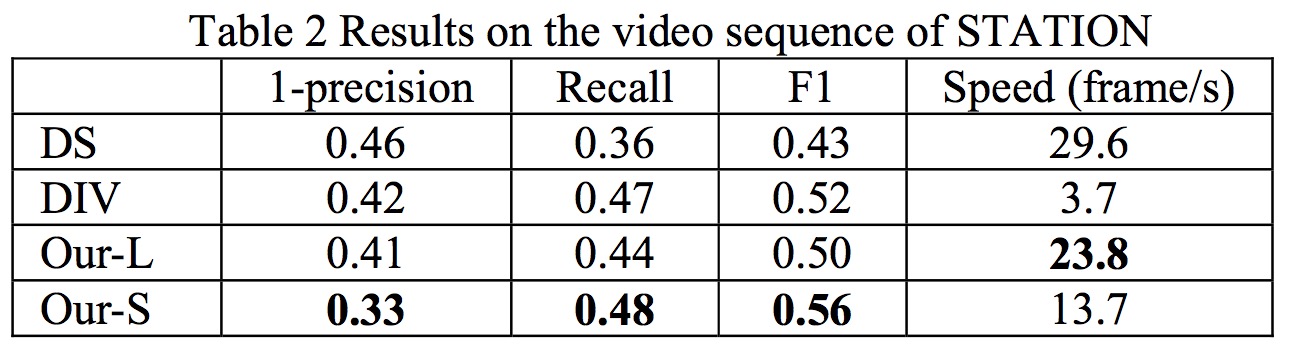
Table 3
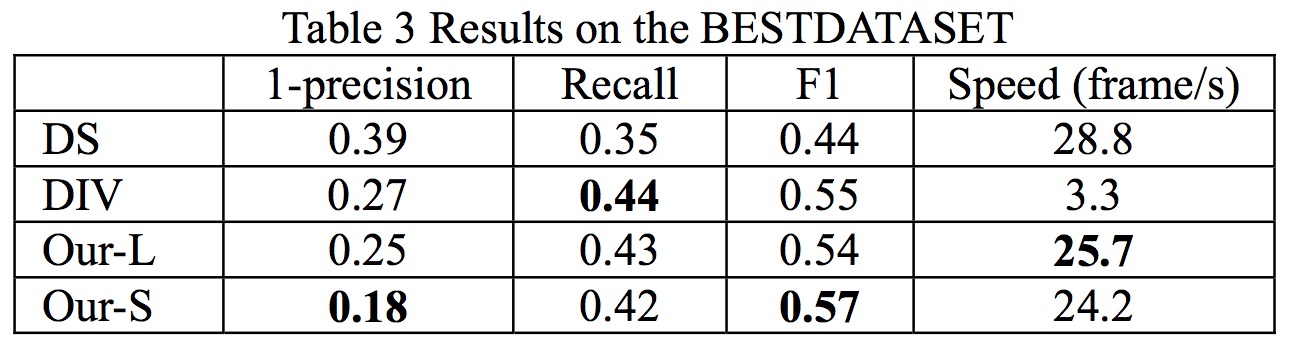
Table 4

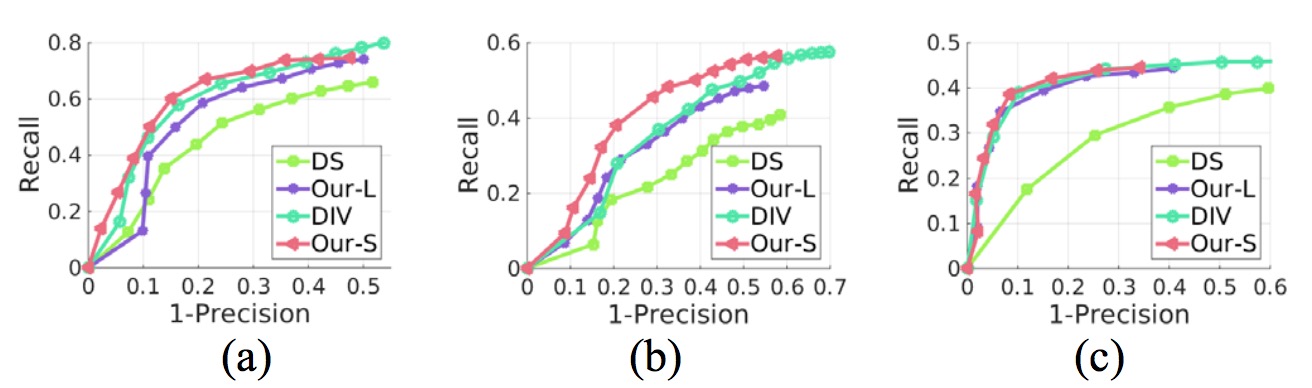
Fig.5 Recall vs 1-Precision Curve. (a) CANTEEN sequence; (b) STATION sequence; (c) BEST dataset.

Fig.6 Examples of detection results on CANTEEN sequence.

Fig.7 Examples of detection results on STATION sequence.

Fig.8 Examples of detection results on BEST dataset.
Dataset
This dataset consists of two real-scene parts. One is part of the public BEST dataset, which containing about 280 pictures; the other is collected by ourself, which contains about 200 images from railway station surveillance video.
Dataset
Citation
Zhang S, Lin W, Lu P, et al. Kill two birds with one stone: Boosting both object detection accuracy and speed with adaptive patch-of-interest composition[C]// IEEE International Conference on Multimedia & Expo Workshops. IEEE Computer Society, 2017:447-452.
Institute of Media, Information, and Network (MIN Lab)
沪交ICP备20160059
.png)

